
iPadで自炊書籍をスキャニングするとき、保存データ形式はおおまかに分けてJpeg(それをzipでまとめる)かPDFにするかどちらかだと思います。
管理人いぬたろうがiPadで閲覧に使うアプリは i文庫HD、Sidebooks、ComicGlass等ですが、中でもJpegのままzipにまとめたものをMediaServer越しに ComicGlass で閲覧することがほとんどだと思います。
※zipにまとめるのは転送の時に1つのファイルとして扱われるので便利だからです。転送せずに共有フォルダを閲覧する場合はフォルダでまとめるだけでもOKです。
![ComicGlass[コミックリーダ]](http://a1880.phobos.apple.com/us/r30/Purple1/v4/c7/bd/82/c7bd82c6-67d5-c8f5-385c-660b5cbec92b/mzl.frkwbvsm.100x100-75.png "ComicGlass[コミックリーダ]")
ComicGlass はComicと名前に冠されているものの文庫、雑誌、写真集等の閲覧にも問題なく使えるのでiPhone・iPadで自炊書籍を読みたい方ならまず購入して損はないアプリだと思います。
そしてアプリ内有料アドオンですが MediaServer plus もぜひ追加購入することをおすすめします。MediaServerを立ち上げる事でPC内の共有フォルダ内のファイルをiPhone・iPadから直接ストリーミング閲覧する事が可能になります。この機能めちゃくちゃ便利です。
あえてPDFファイルで作成すべき自炊書籍ジャンル
Jpegのまま閲覧できるのが一番手間のない方法ですが、中にはPDFで作るべき自炊書籍データも有ります。
代表的なものはマニュアル本の類でしょうか。
それらは語句を検索して素早く目的のページを見つけなければならないのでOCRがかかったPDFデータにするのが最適です。
ということで今回は本文内検索できるPDFを作成する方法を記事にしたいと思います。
ドキュメントスキャナがあればPDF作成は簡単
書籍を自炊してPDFデータを作成したい場合、素直にドキュメントスキャナを購入しましょう。フラットベットスキャナやスマートフォンカメラを使って1枚づつ取り込んで行く方法は手間が掛かり過ぎで現実的ではありません。
ドキュメントスキャナの代表機種といえば Fujitsu ScanSnap シリーズです。
管理人いぬたろう ScanSnap ではなく同じ Fujitsu の fi-6130z というドキュメントスキャナを使用していますが、こちらの機種にも ScanSnapMode があり、ScanSnap 同様にOCR処理されたPDFファイルを簡単に作成可能です。
今回の記事では扱いませんが fi-6130z では更に高度に詳細な設定をして用途別に最適な自炊データを作成可能です。
fi-6130z (現行機種はUSB3.0対応で更に高速になったfi-7160)
スタンダード機種である ScanSnap iX500 との最大の違いは背景色黒でスキャニングが可能であったり(裏写りが気にならない)、TIFF無圧縮で画質劣化の少ないデータが転送出来たり、ドキュメントスキャナの枠を超えた使い方が可能な事だと思います。
特に雑誌等出来るだけ画質を保ったまま大量にスキャニングするという用途を考えている方はこのグレード以上の機種を選定するほうをおすすめします。
画質に関しては以前の記事を参考にして下さい。

ScanSnapModeをつかって簡単PDF作成
試しに ScanSnapMode で出来るだけ簡単にPDF作成するまでの設定をしてみます。
ScanSnapMode の設定
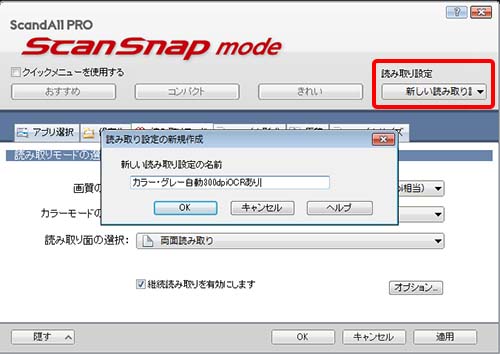
●右上 読取り設定 より→ 新しい読取り設定の新規作成 で設定を作成します。今回は”カラー・グレー自動300dpiOCRあり”という名前にしました。
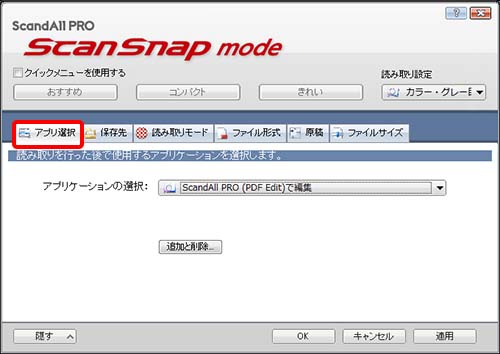
●アプリ選択タグで アプリケーションの選択 → ScandAll PRO (PDF Edit)で編集 を選択します。
ScandAll PRO (PDF Edit) はスキャニングされたPDFデータのページの挿入 ページの削除 回転等が出来るアプリケーションでこちらで目視確認をして最終的にPDFファイルを保存作成します。
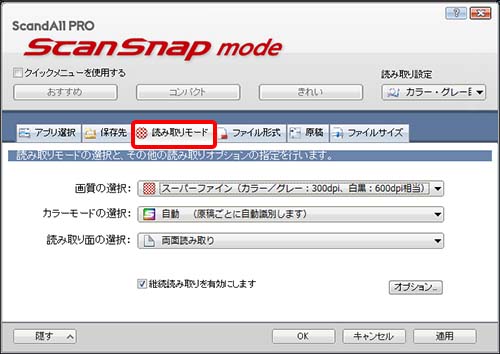
●読み取りモードタグで 画質の選択 → スーパーファイン(カラー/グレー:300dpi、白黒:600dpi相当)、カラーモードの選択 → 自動 、読み取り面の選択 → 両面読み取り 、継続読み取りを有効にします にチェックを入れます。
特にOCRの精度を上げるためには解像度が必要なので 画質の選択 → スーパーファイン を選択して下さい。
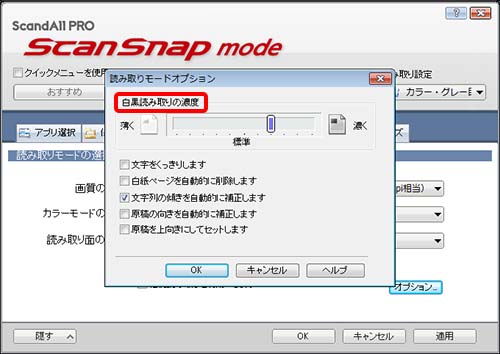
更に オプション より 白黒読み取りの濃度 のスライダーを少し濃い目に。下の項目は 文字列の傾きを自動的に補正します にチェックします。
白黒読み取りの濃度は 標準ではグレーの部分がほぼ白く補正され消えてしまうので好みですが少し濃い目に設定しました。(※バックがグレーの部分に文字が乗っている場合OCR精度が下がるので、OCR精度を優先する場合は標準のままのほうがよいです。)
白紙ページを自動的に削除します はページ構成が変わると見開きページで都合が悪くなるので通常はチェックを外します。
文字列の傾きを自動的に補正します はページ内の文字列を参考にして傾きを自動的に補正します。しかし必ずしも完璧に正しく補正されるわけでもなく、またページによってはかえって激しく傾く原因になったりします。その場合はチェックを外します。
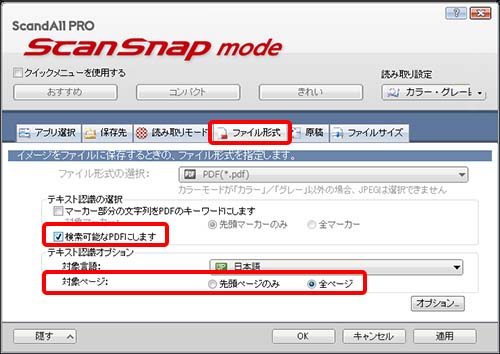
●ファイル形式タグより 検索可能なPDFにします をチェック、対象ページを 全ページ にチェックします。
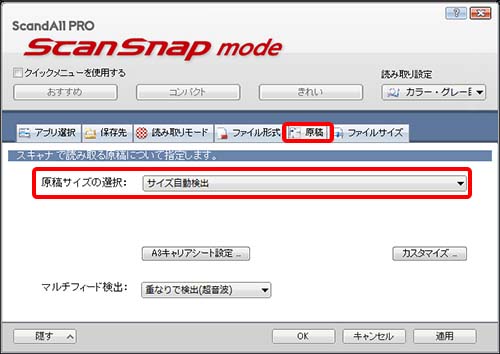
●ScanSnap iX500 などの場合は 読み取りモードオプションの中に 裏写りを軽減します というチェック項目があります。
fi-6130z の場合は 原稿サイズの選択 を サイズ自動検出 にすると自動的に 黒背景 が選ばれ裏写りのない(目立たない)ファイルが出来上がります。
●ファイルサイズタグは特に変更しません。
下の 適用 を押して設定は完了です。
タスクバーアイコンより左クリックで使用する”読み取り設定”を選択して、右クリックで ”両面読み取り” または ”片面読み取り” を選択すればスキャニングがスタートします。
スキャニング後 OCR処理が自動的にスタート
●A5判250ページ程度でOCR処理に15分程度かかりました。
OCRがかけられたPDFがScandAll PRO (PDF Edit) に送られる
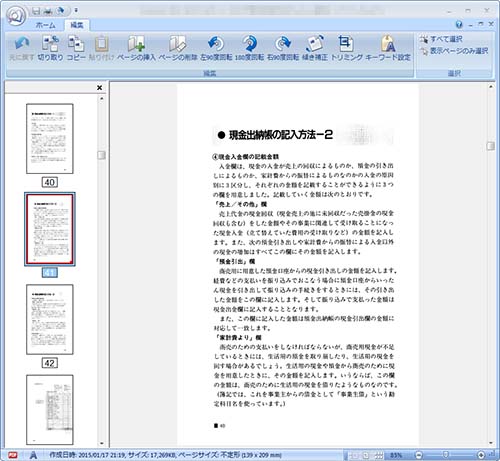
●ScandAll PRO (PDF Edit) ではスキャン後OCRがかけられたPDFファイルのページの順番を入れ替えたり、ページの挿入、削除、トリミング等が可能です。
※手動での傾き補正も可能ですがOCRテキスト情報は削除されます。
プレビュー内容を確認してOKであれば名前を付けて保存します。
参考ですが、文字多めの270ページの書籍で16.8Mbyte位のサイズになりました。
PDFデータ完成
●完成したPDFデータをiPadに転送 Sidebooks で表示してみます。

自動的に色処理され文字も読みやすく補正されたPDFデータになりました。
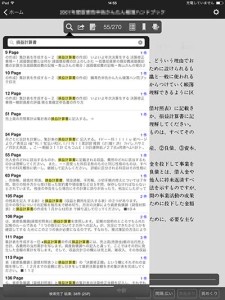
もちろん語句の本文検索も可能です。
まとめ
●設定が複雑になりがちな業務機である Fujitsu fi-6130z ですが ScanSnapMode を使用することにより簡単にOCRがかかったPDF作成を作成する事が可能です。
またスキャニング速度、紙送り機構、裏写り対策などの基本性能の高さは自炊ヘビーユーザーなら特に有り難みを感じるのではないかと思います。

