OCRがかかったPDFを作成するとき ClearScan を使って変換するという選択肢も有ります。
ClearScan はPDFの開発元であるAdobe社のAcrobatで利用出来る技術で、OCRを適用して変換されたテキストデータを元画像と置き換えて直接表示させる形式です。
確かにわざわざテキストに変換するのだからそのままそれを表示できれば一番無駄のないデータが出来上がるわけですが、現状まだまだ完璧とはいえない状況も多いです。
今回はその ClearScan の使い勝手を検証していきたいと思います。
以下便宜上、画像の上にOCR変換された透明なテキストデータをかぶせた従来通りのPDFを ”画像PDF”
Adobe社のAcrobatでClearScanで変換されたPDFを ”ClearScan PDF” と呼ぶことにします。
fi-6130zからAcrobatでClearScanをかける
前回、前々回同様出来るだけ手のかからない方法をということで ScanSnapMode でまずPDFを作成します。
その後 Adobe Acrobat Pro または Standard に送り ClearScan を適用します。
ScanSnapMode
基本的な設定はこちらで解説しています。

設定の変更箇所は
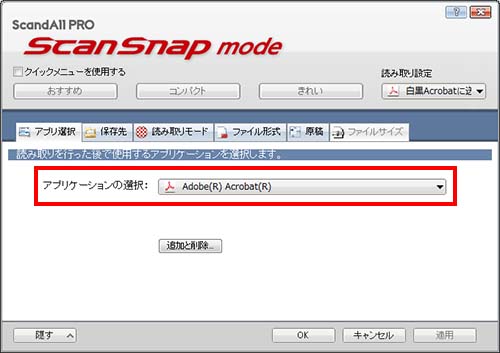
●アプリ選択タグで アプリケーションの選択 → Adobe(R) Acrobat(R) を選択します。
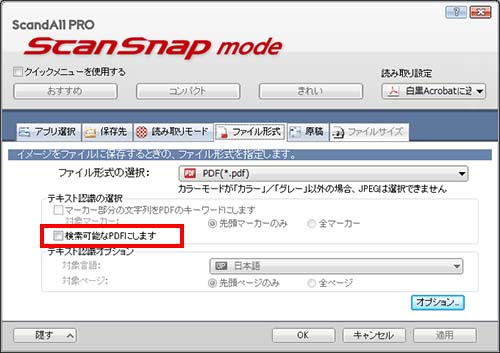
●ファイル形式タグより 検索可能なPDFにします のチェックを外します。
Acrobat
※ClearScan を使用する為には Adobe Acrobat Pro または Standard が必要です。
スキャン終了後PDFデータが Acrobat に送られます。
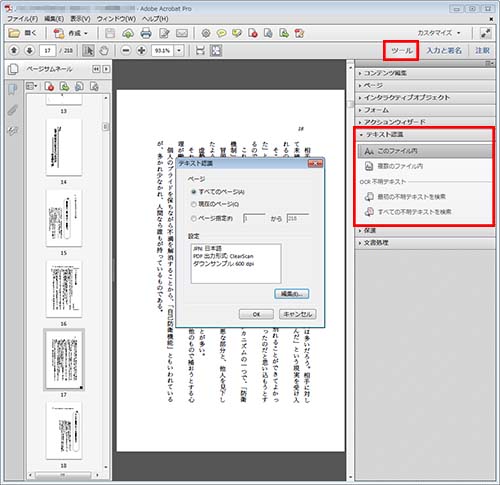
●Acrobat Pro → ツール → テキスト認識 → このファイル内 → 設定 → PDFの出力形式 ClearScan → OK
でOCR変換がスタートします。
変換時間は
約250ページの横書き書籍で
画像PDF ……15分
ClearScan PDF ……17分
程度かかりました。
ClearScanのメリット
データ量の削減
書籍のタイプによりますが、テキスト中心の書籍であれば大幅なサイズダウンが期待できます。
参考に220ページテキスト中心の書籍で
画像PDF ……8.5Mbyte
ClearScan PDF ……4.5Mbyte
とおよそ半分のサイズになりました。
拡大してもキレイ
画像PDF は拡大すれば文字のエッジが汚くなりますが、ClearScan PDF なら近い書体のフォントデータに変換されているため拡大してもキレイです。

ちなみにタブレット等での表示等が軽快になるという効果もあるようですが、管理人いぬたろう使用のiPad Air 2上ではその違いは感じられませんでした。
ClearScanのデメリット
誤変換
元原稿の状態やレイアウト等がまちまちな状態では100%正確な変換ができる時代がくるのはおそらく難しいでしょう。なので誤変換はこれからもずっとつきまとう問題です。
100%正確な変換にするためには人間の脳のようにコンピュータが文脈を推測して変換する事が必要になると思います。
誤変換だけの話なら 画像PDF ・ ClearScan PDF とも同じデメリットなんですが、 ClearScan PDF の場合は元画像が残らないので正しい情報を確認出来ないという問題があります。
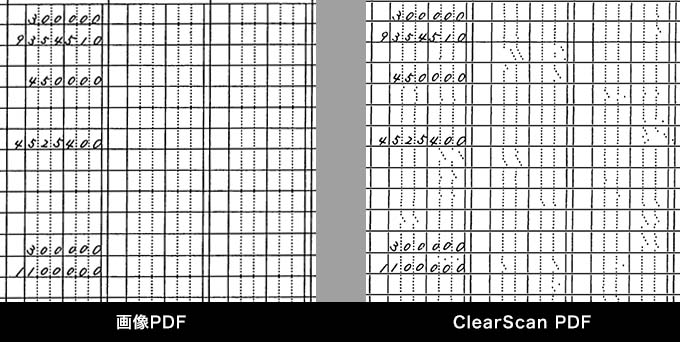
●誤変換の例…… ClearScan PDF はレイアウトが大きく崩れました。
ClearScan の使い道
データ保存機器の大容量化、CPUの高速化などによって自炊データをギリギリにダイエットする必要性は徐々になくなってきており、正直 画像PDF を ClearScan PDF にわざわざ誤変換の危険を伴ってまで置き換えるべきなのかというと疑問です。
管理人いぬたろう的には現時点では ClearScan PDF を積極的に使う事はないと思います。
ただPDF開発元のAdobeが更に力をいれて改良していけば将来的には無くてはならないすばらしい技術になるかもしれません。
まとめ
●書籍をデジタルデータとして残すという自炊という行為を考えればデータが不完全な形になる危険性がある ClearScan PDF はまだまだ実践的ではないと個人的には感じています。
しかしすばらしい技術で有ることは確かだと思うので、バージョンアップに期待しておこうかなと思ったり思わなかったりしています。

